تحلیل داده یکی از امیدوارکنندهترین علوم برای ساخت آینده است. در فرایند تحلیل داده حجم وسیعی از دادهها هر لحظه، به کمک دیتاست پردازش میشوند. سیستمهای کاری جدید و برنامههای کاربردی تخصصی که بهطور مداوم در حال توسعه هستند هم به مجموعهای از دادههای دیتاست نیاز دارند. برای آنکه بدانیم دیتاست چیست و چه مزایا و قابلیتهایی دارد در این مقاله همراه ما باشید.
دیتاست چیست؟
دیتاست مجموعهای ساختاریافته از دادههای مرتبط است که در قالب سطرها و ستونها سازماندهی میشود و اطلاعات مربوط به یک دسته یا حوزه مشخص را نمایش میدهد. دیتاستها زیربنای بسیاری از عملیات، تکنیکها و مدلهایی هستند که در صنایع مختلف مورد استفاده قرار میگیرند. مثلا یک دیتاست دانشاموزی سطرهایی برای هر دانشآموز و ستونهایی برای ویژگیهایی مانند نام، سن، پایه تحصیلی و نمرات دارد.
اهمیت دیتاست
برخی از موارد که نشان میدهند دیتاستها در تحلیل داده و یادگیری ماشین اهمیت دارند عبارتاند از:
- تحلیل: مواد خام موردنیاز برای تحلیل و تصمیمگیری را فراهم میکنند.
- آموزش مدلهای یادگیری ماشین: امکان آموزش و آزمون مدلهای یادگیری ماشین و هوش مصنوعی را فراهم میسازند.
- کشف الگوها و همبستگیها: به شناسایی الگوها، همبستگیها و بینشها در حوزههای مختلف کمک میکنند.
- نوآوری: از پژوهش و توسعه در صنایعی مانند سلامت، مالی و آموزش پشتیبانی میکنند.
- ارزیابی و استانداردها: امکان بازتولیدپذیری نتایج و بنچمارکگذاری را در پروژههای دانشگاهی و حرفهای فراهم میآورند.
برای شرکت در دوره تحلیل داده دانشکار روی این دکمه کلیک کنید:
انواع دیتاست چیست؟
دیتاستهای مختلفی وجود دارند که برخی از مهمترین آنها عبارتاند از:
- دیتاست عددی: شامل دادههای عددی است که میتوان آنها را با روشهای ریاضی یا آماری تحلیل کرد؛ برای مثال دیتاست دما.
- دیتاست دستهای: نمایانگر دستهها یا گروههای گسسته مانند رنگ، جنسیت، شغل یا ورزش است.
- دیتاست سری زمانی: دادهها را در طول یک بازه زمانی ثبت میکند تا روندها یا تغییرات قابل پیگیری باشند؛ مانند قیمت سهام.
- دیتاست ترتیبی: شامل دادههای رتبهبندیشده یا ترتیبی است که در آنها ترتیب اهمیت دارد، اما اختلاف دقیق بین مقادیر مشخص نیست؛ مانند نظرات مشتریان، امتیازدهی نظرسنجیها یا رتبهبندی فیلمها.
- دیتاست تصویری: از مجموعهای از تصاویر تشکیل شده است که برای وظایفی مانند طبقهبندی، شناسایی یا تحلیل استفاده میشود؛ برای مثال تصاویر پزشکی برای تشخیص بیماری.
- دیتاست وب: از طریق APIها یا منابع وب جمعآوری میشود و در قالبهای ساختیافتهای مانند JSON برای تحلیلهای بعدی ذخیره میگردد.
- دیتاست مبتنی بر فایل: در فایلهایی مانند CSV، اکسل (.xlsx) یا فایلهای متنی ذخیره میشود تا دسترسی و پردازش آن آسان باشد.
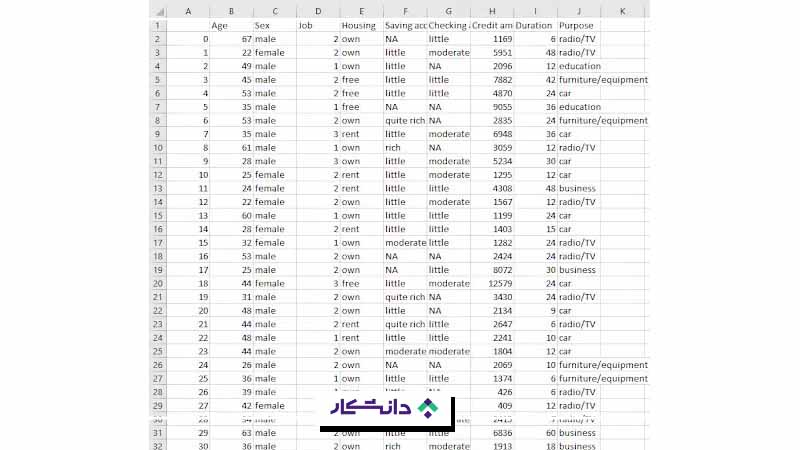
ویژگیهای دیتاست
در ادامه، مهمترین ویژگیهایی که یک دیتاست را تعریف میکنند نوشته شده است:
- مرکز دادهها: به مقدار میانی یک دیتاست اشاره دارد و با میانگین، میانه یا نما اندازهگیری میشود. این ویژگی نشان میدهد که بیشتر مقادیر داده در چه محدودهای قرار دارند و درک کلی از مقدار متوسط دادهها ارائه میدهد.
- چولگی دادهها: میزان تقارن توزیع دادهها را نشان میدهد. یک توزیع کاملاً متقارن مانند توزیع نرمال دارای چولگی صفر است، در حالی که چولگی مثبت یا منفی نشاندهندهٔ تمایل توزیع به یک سمت خاص است.
- پراکندگی: بیانگر میزان پراکندگی دادهها حول مرکز است. معیارهایی مانند انحراف معیار یا واریانس برای سنجش این ویژگی بهکار میروند و نشان میدهند دادهها تا چه اندازه از مقدار متوسط فاصله دارند.
- دادههای پرت: نقاط دادهای هستند که بهطور قابلتوجهی خارج از الگوی کلی قرار میگیرند. شناسایی دادههای پرت اهمیت زیادی دارد، زیرا میتوانند بر نتایج تحلیل تأثیر بگذارند و نیازمند بررسی بیشتر باشند.
- همبستگی: میزان ارتباط بین متغیرها را نشان میدهد. همبستگی مثبت به این معناست که با افزایش یک متغیر، متغیر دیگر نیز افزایش مییابد؛ همبستگی منفی نشاندهنده حرکت متغیرها در جهتهای مخالف است و نبود همبستگی بیانگر فقدان رابطه مشخص میان آنهاست.
- توزیع احتمال: شناخت نوع توزیع دادهها مانند نرمال، یکنواخت یا دوجملهای به ما کمک میکند احتمال وقوع مقادیر مختلف را پیشبینی کنیم و روشهای آماری مناسبتری برای تحلیل دادهها انتخاب نماییم.
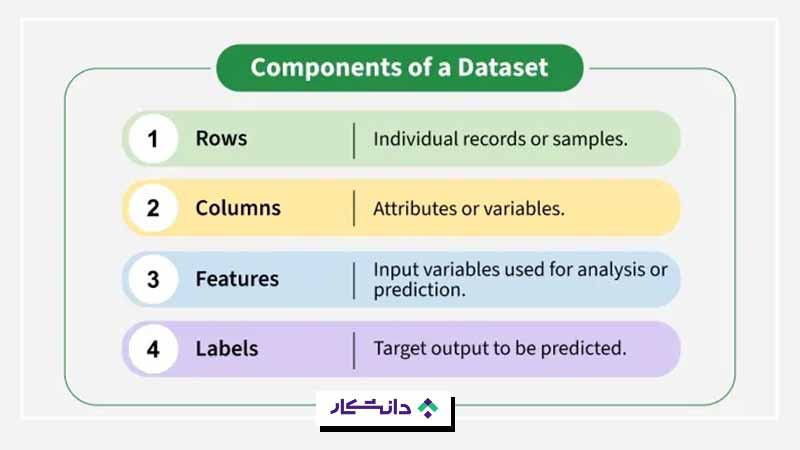
قابلیت دیتاست چیست؟
برخی از ویژگیهای رایج یک دیتاست عبارتاند از:
- ویژگیهای عددی: شامل مقادیر عددی مانند قد، وزن و موارد مشابه هستند. این ویژگیها میتوانند پیوسته در یک بازه مشخص باشند یا بهصورت متغیرهای گسسته تعریف شوند.
- ویژگیهای دستهای: شامل چندین کلاس یا دسته مانند جنسیت، رنگ و موارد مشابه هستند.
- اندازه داده: به تعداد رکوردها و ویژگیهایی اشاره دارد که در فایل حاوی دیتاست وجود دارد.
- رکوردهای داده: به مقادیر منفرد دادهها اشاره دارد که در دیتاست ثبت شدهاند.
- متغیر هدف: مهمترین ویژگی در یک دیتاست است که قصد داریم آن را با استفاده از سایر ویژگیها پیشبینی یا تبیین کنیم.
عملیات روی دیتاستها
برخی از عملیات اصلی که روی دیتاستها با استفاده از کتابخانههای pandas و numpy در پایتون انجام میشود عبارتاند از:
بارگذاری و خواندن دیتاستها
وارد کردن دادهها به محیط کاری از منابعی مانند CSV، JSON، پایگاههای داده SQL، APIها و … در این مرحله انجام میشود و میتوانید از تکنیکهای زیر استفاده کنید:
- read_csv()
- read_json()
- read_excel()
تحلیل اکتشافی دادهها
درک بهتر دیتاست از طریق خلاصهسازی، بررسی توزیعها و شناسایی الگوها انجام میشود. از پرکاربردترین تکنیکهای این مرحله میتوان به موارد زیر اشاره کرد:
- head()
- tail()
- groupby()
پیشپردازش دادهها
پاکسازی دادهها، مدیریت مقادیر گمشده، کدگذاری، مقیاسبندی و آمادهسازی دادهها برای استفاده در مدلها از اقدامات پیشپردازش دادهها هستند. از تکنیکهای زیر میتوانید در این مرحله استفاده کنید:
- drop()
- fillna()
- dropna()
- copy()
دستکاری دادهها
تغییر یا تبدیل دادهها مانند فیلتر کردن، گروهبندی، ادغام و تغییر شکل دادهها در این مرحله انجام میشود. از تکنیکهای زیر برای دستکاری دادهها استفاده کنید:
- merge()
- concat()
- join()
مصورسازی دادهها
نمایش دادهها بهصورت نمودارها، گرافها یا داشبوردها به دریافت بهتر اطلاعات کمک میکند. برای مصورسازی دادهها از تکنیکplot() استفاده کنید.
شاخصگذاری دادهها
دسترسی و سازماندهی کارآمد دادهها به کمک برچسبهای سطر و ستون، کلیدها یا اندیسها انجام میشود. در این مرحله از شاخصگذاری دادهها از تکنیک iloc() استفاده کنید.
خروجی گرفتن از دادهها
ذخیرهسازی دادههای پردازششده در قالبهایی مانند CSV، Excel، JSON یا پایگاههای داده برای استفادههای بعدی انجام میشود. تکنیکهای زیر مناسب خروجی گرفتن از دادهها هستند:
- to_csv()
- to_json()
تفاوت داده، پایگاه داده و دیتاست چیست؟
دادهها واحدهای فردی از اطلاعاتی مانند اعداد، دستهها یا ویژگیها هستند که نمیتوان آنها را به تنهایی تحلیل کرد. دیتاست مجموعهای از دادههای مرتبط ساختاریافته یا بدون ساختار است که در تحلیل یا ساخت مدل استفاده میشود. پایگاه داده سیستمی است از چندین دیتاست مرتبط یا نامرتبط که میتوان برای کاربردهای مختلف از کوئریهای آن استفاده کرد. جدول مقایسه داده، دیتاست و پایگاه داده در این بخش نوشته شده است:
| موضوع | داده | دیتاست | پایگاه داده |
|---|---|---|---|
| تعریف | حقایق خام یا اطلاعات پایه بدون زمینه | مجموعهای ساختیافته از ورودیهای دادهٔ مرتبط | مجموعهای سازمانیافته از دیتاستها که بهصورت نظاممند ذخیره شدهاند |
| ساختار | بدون ساختار درونی و نامنظم | سازمانیافته در قالب سطر و ستون | سازمانیافته در قالب جداول، اغلب در چندین بُعد |
| نقش | زیربنای دیتاستها و پایگاههای داده | ساختدهی به دادهها و ایجاد بینش معنادار | تعریف و مدیریت گسترده روابط بین ویژگیها |
| تغییر | به دلیل نبود ساختار، بهطور مستقیم قابل دستکاری نیست | با ابزارهایی مانند Tableau، Power BI و پایتون قابل تحلیل و مصورسازی است | از طریق کوئریها، تراکنشها و اسکریپتها قابل دستکاری است |
| کاربرد | پیش از استفاده نیازمند پیشپردازش و تبدیل است | برای تحلیل داده، مدلسازی و مصورسازی استفاده میشود | برای کوئریگیری، انجام تراکنشها و مدیریت برنامهها بهکار میرود |
چالشهای کار با دیتاست چیست؟
چالشهای رایج هنگام کار با دیتاستها عبارتاند از:
- مشکلات کیفیت: دادههای گردآوریشده ضعیف یا ناسازگار میتوانند تحلیل را گمراه کنند و دقت مدلها را کاهش دهند.
- دادههای گمشده: رکوردهای ناقص شکافهایی ایجاد میکنند که نتیجهگیری قابل اعتماد یا آموزش موثر مدلها را دشوار میسازد.
- سوگیری: زمانی که دیتاستها نامتوازن یا غیرنماینده باشند، مدلهای حاصل ممکن است نتایج ناعادلانه یا جهتدار تولید کنند.
- مقیاسپذیری: دیتاستهای بسیار بزرگ با منابع محدود، پاکسازی، ذخیرهسازی و پردازش کارآمد را چالشبرانگیز میکنند.
- ملاحظات حریم خصوصی: دادههای حساس یا شخصی نیازمند مدیریت سختگیرانه برای انطباق با استانداردهای حریم خصوصی و امنیت هستند.
کاربردهای دیتاست چیست؟
برخی از کاربردهای مهم دیتاستها عبارتاند از:
- آموزش یادگیری ماشین: دیتاستها برای آموزش مدلها در وظایفی مانند تشخیص تصویر، پردازش زبان طبیعی (NLP) یا کشف تقلب استفاده میشوند.
- تحلیل کسبوکار: شرکتها دیتاستهای فروش، مشتریان و مالی را تحلیل میکنند تا تصمیمهای آگاهانه بگیرند.
- سلامت: سوابق بیماران، تصاویر پزشکی و دیتاستهای ژنومی از تشخیص بیماری و برنامهریزی درمان پشتیبانی میکنند.
- آموزش و پژوهش: دیتاستهای عمومی به دانشجویان و پژوهشگران کمک میکنند آزمایش انجام دهند، فرضیهها را اعتبارسنجی کنند و راهکارهای جدید بسازند.
- سیستمهای توصیهگر: دیتاستهای رفتار کاربر مانند خریدها، کلیکها و امتیازدهیها برای پیشنهاد محصولات، فیلمها یا موسیقی بهکار میروند.

معرفی ۳ نمونه دیتاست ایرانی
دادهها یکی از مهمترین بخشهای هر پروژه هوش مصنوعی و دیتاساینس هستند. از اینرو مدلها برای یادگیری الگوها و ارائه پیشبینیهای دقیق به دادههای مناسب نیاز دارند. در ایران نیز دیتاستهای مختلفی در حوزههایی مانند پردازش زبان فارسی، تحلیل رفتار کاربران، املاک، تصاویر و شبکههای اجتماعی جمعآوری شدهاند. در ادامه چند نمونه از دیتاستهای ایرانی و کاربرد هر یک را بررسی کردهایم.
۱. دیتاست کلمات اسپم پیامک فارسی؛ تشخیص پیامکهای ناخواسته
این دیتاست شامل مجموعهای از کلمات فارسی مرتبط با پیامکهای اسپم است. شما میتوانید برای پروژههای پردازش زبان طبیعی (NLP) و دستهبندی متن از آن استفاده کنید. با تحلیل این دادهها میتوان مدلهایی برای شناسایی پیامکهای تبلیغاتی و ناخواسته، فیلتر کردن محتواهای مزاحم و بهبود سیستمهای تشخیص اسپم ایجاد کرد.
۲. دیتاست آگهیهای دیوار؛ پیشبینی قیمت و تحلیل بازار املاک
دیتاست آگهیهای دیوار مجموعهای از اطلاعات آگهیهای ثبتشده مانند قیمت، ویژگیهای ملک و مشخصات آگهیهاست. این دادهها برای ساخت مدلهای یادگیری ماشین در حوزه املاک کاربرد دارند. برای مثال شما میتوانید به کمک این دیتاست قیمت ملک را پیشبینی کرده، روند بازار را تحلیل کنید یا عوامل تأثیرگذار بر قیمت را بررسی کنید.
۳. دیتاست هنرمندان ایرانی اسپاتیفای؛ تحلیل دادههای موسیقی
این دیتاست شامل اطلاعات هنرمندان ایرانی در اسپاتیفای است. شما میتوانید برای پروژههای تحلیل داده در حوزه موسیقی از دیتاست هنرمندان ایرانی اسپاتیفای استفاده کنید. با بررسی ویژگیهایی مانند هنرمندان، محبوبیت و دادههای مرتبط با موسیقی میتوانید پروژههایی مانند تحلیل روندهای موسیقی، دستهبندی هنرمندان یا بررسی الگوهای محبوبیت را انجام دهید.
منبع: Geeksforgeeks.com