

پایگاههای داده، اجزای ضروری بسیاری از برنامهها و ابزارهای مدرن هستند. بهعنوان یک کاربر، ممکن است هر روز هنگام بازدید از وبسایتها، استفاده از اپلیکیشنهای گوشی یا خرید از فروشگاهها، با دهها یا حتی صدها پایگاه داده تعامل داشته باشید. بهعنوان یک توسعهدهنده، پایگاههای داده جزء اصلی برای ذخیره و نگهداری دادهها فراتر از طول عمر اجرای برنامه شما هستند. برای آشنایی بیشتر با پایگاه داده، انواع و کاربردهای آن در این مطلب از مجله دانشکار همراه ما باشید.
پایگاه داده چیست؟
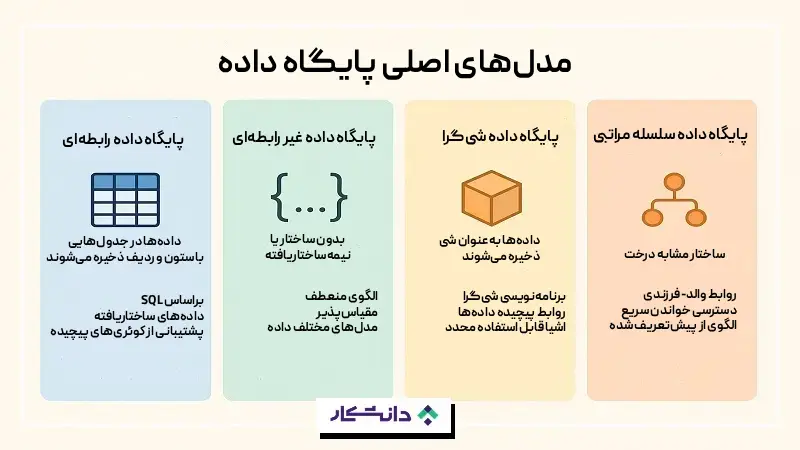
پایگاه داده منبع دیجیتال ذخیره، مدیریت و ایمنسازی مجموعهای از دادههای ساختاریافته است. هر پایگاه داده روش مختلفی برای ذخیره دادهها دارد. بهعنوان مثال پایگاههای داده رابطهای دادهها را در جداول تعریفشده با ردیفها و ستونهای مشخص ذخیره میکنند. درحالیکه پایگاههای داده غیررابطهای میتوانند دادهها را در قالب ساختارهای دادهای متنوع، مانند نمودارها، ذخیره کنند.
سازمانها از انواع مختلف پایگاههای داده برای مدیریت دادههای متنوع استفاده میکنند. پایگاههای داده رابطهای مناسب دادههای ساختاریافته، مانند سوابق مالی هستند. در مقابل پایگاههای داده غیررابطهای برای دادههای بدون ساختار مانند فایلهای متنی، فایلهای صوتی و ویدیو مناسب هستند. پایگاههای داده برداری دادهها را بهصورت نشانههای برداری ذخیره میکنند. این فرمت در بسیاری از هوش مصنوعیهای مولد استفاده میشود.
کسبوکارها دادههای بسیاری در اختیار دارند که واحد آن معمولا پتابایت یا کوادریلیون است. از جمله این دادهها میتوان به تراکنشهای مشتریان، موجودی محصولات، فرایندهای داخل سازمان و تحقیقات منحصربهفرد اشاره کرد. برای آنکه کاربران و نرمافزارها هنگام نیاز به این اطلاعات دسترسی داشته باشند دادهها باید منسجم و منظم سازماندهی شوند.
برای ایجاد چنین معماری داده به پایگاه داده نیاز است. این پایگاهها صرفا محلی برای ذخیره اطلاعات نیستند و به سازمانها کمک میکنند دادههای خود را با تمرکز مدیریت کنند، استاندارد یکپارچه و امنیت داده داشته باشند و دسترسی به اطلاعات آسانتر میشود. با استفاده از سیستمهای پایگاه داده مناسب، سازمانها میتوانند از مجموعه دادهها باکیفیت برای پیشرفتن پروژهها و ابتکارهای مهم کسبوکارشان استفاده کنند. از جمله این کاربردها میتوان به هوش تجاری (BI)، هوش مصنوعی (AI) و پروژههای یادگیری ماشین (ML) اشاره کرد.
پایگاه داده چه چیزی نیست؟
اکثر افراد از عبارت پایگاه داده برای موارد کلی و نهچندان دقیق استفاده میکنند. این موضوع باعث ایجاد ابهام درباره ماهیت واقعی پایگاه داده و تفاوت آن با سایر فناوریها میشود. پایگاه داده سیستم ذخیرهسازی و مدیریت دادهها است که شامل سختافزار فیزیکی محل ذخیره اطلاعات، نرمافزار سازماندهی داده و کنترل دسترسی به آنها میشود.
پایگاههای داده زیربنای بخش بزرگی از زیرساختهای فناوری اطلاعات مدرن، مانند وبسایتها، اپلیکیشنها و پلتفرمهایی مانند آمازون و گوگل هستند. البته این سرویسها اصل پایگاه داده نیستند، بلکه برای مدیریت اطلاعاتی مانند موجودی محصولات، اطلاعات کاربران یا نتایج جستجو به پایگاه داده نیاز دارند.
نکته: نرمافزار اکسل پایگاه داده محسوب نمیشود و برنامه صفحهگسترده است. اکسل دادهها را در قالب سطرها و ستونها سازماندهی میکند و در این مورد شبیه پایگاه داده رابطهای است. اما هر فایل اکسل یک فایل مستقل است. در مقابل پایگاههای داده سیستمهای قدرتمند و متمرکزی هستند که انواع دادهها را در قالبهای مختلف ذخیره میکنند و در عین حال از قابلیتهای پیشرفتهتری مانند جستجوها و بررسیهای پیچیده پشتیبانی میکنند. به همین دلیل پایگاههای داده برای مدیریت حجم زیاد اطلاعات در سازمانها و نرمافزارهای بزرگ مناسبتر از اکسل هستند.
انواع پایگاه داده
سازمانها از انواع مختلف پایگاه داده برای مدیریت دادهها و پشتیبانی از برنامههای گوناگون استفاده میکنند. برخی از رایجترین انواع پایگاههای داده عبارتاند از:
- پایگاه داده ناوبری (navigational)
- پایگاه داده رابطهای
- پایگاه داده غیررابطهای یا NoSQL
- پایگاه داده شیگرا
- پایگاه داده برداری
- پایگاه داده ابری
پایگاه داده ناوبری
پایگاههای داده ناوبری دادهها را در مجموعهای از رکوردهای بههمپیوسته ذخیره میکند. کاربران برای دسترسی به داده مورد نظر خود باید در میان این رکوردهای مرتبط حرکت کنند. به همین دلیل به آن پایگاه داده ناوبری میگویند. پایگاههای داده سلسلهمراتبی و پایگاههای داده شبکهای دو نوع رایج پایگاههای داده ناوبری هستند.
- پایگاه داده سلسلهمراتبی: در این پایگاه داده، اطلاعات در ساختاری شبیه به درخت سازماندهی میشوند و شامل رکوردهای والد و رکوردهای فرزند هستند. هر رکورد فرزند فقط میتواند یک والد داشته باشد. هر رکورد والد میتواند چند فرزند داشته باشد. برای رسیدن به یک رکورد خاص، کاربر باید از بالاترین سطح ساختار شروع کرده و کمکم به سمت شاخههای پایینتر حرکت کند. برای مثال در یک سازمان شرکت میتواند والد واحد باشد و هر واحد نیز والد کارمندان خود است.
- پایگاه داده شبکهای: عملکرد پایگاههای داده شبکهای مشابه پایگاههای داده سلسلهمراتبی است اما در آن هر رکورد فرزند میتواند به چندین رکورد والد متصل باشد. کاربران باید از طریق رکوردهای مرتبط حرکت کنند و با استفاده از اشارهگرها و میتوانند به داده مورد نظر دسترسی داشته باشند.
پایگاههای داده ناوبری زمانی بسیار رایج بودند اما پیشرفت فناوریهای پایگاه داده باعث توسعه مدل داده رابطهای شده است که از محبوبیت این پایگاهها کم میکند.
مثال پایگاه داده ناوبری: سیستمهای مسیریابی مانند نشان و بلد
در اپلیکیشنهای مسیریابی کاربر بین دادههای مربوط به هم حرکت میکند. برای مثال کاربر میتواند از موقعیت فعلی خود به یک خیابان، از خیابان به مسیرها و از مسیر به مقصد برسد. پایگاه داده ناوبری باعث تسریع دسترسی به دادههایی میشود که ارتباط مشخص و از پیش تعیین شده دارند. از اهمیت این دیتابیسها میتوان به مدیریت ارتباط بین مکانها، مسیرها و نقاط جغرافیایی اشاره کرد.
پایگاههای داده رابطهای
این پایگاه داده، دادهها را در جدولهای ساختاریافته شامل سطرها و ستونها ذخیره میکنند. در برخی مواقع به آنها پایگاههای داده SQL میگویند. زیر بسیاری از پایگاههای داده رابطهای از زبان پرسوجوی ساختاریافته (SQL) برای جستجو و مدیریت دادهها پشتیبانی میکنند.
هر جدول در یک پایگاه داده رابطهای شامل اطلاعات مربوط به یک نوع موجودیت است. بهعنوان مثال یک سازمان ممکن است جدولی شامل اطلاعات تمام مشتریان خود داشته باشد و در کنار آن، جدولهای جداگانهای برای ثبت تاریخچه خرید هر مشتری نگهداری کند.
مدل رابطهای در دهه ۱۹۷۰ توسط ادگار کد دانشمند IBM، توسعه داده شد. از آنجایی که فرآیند بازیابی داده در مدل رابطهای سادهتر است این مدل بهسرعت محبوبتر از مدل ناوبری شد. به جای مشخص کردن مسیرهای دسترسی میان رکوردها، میتوانید با استفاده از دستورات SQL داده مورد نظر خود را مشخص کنید. سپس پایگاه داده نحوه بازیابی رکوردهای مرتبط را تعیین میکند و اغلب برای افزایش سرعت بهجای اسکن کامل جدولها از ایندکس استفاده میشود.
پایگاههای داده رابطهای میزان افزونگی دادهها را کاهش میدهند. زیرا هر داده تنها یکبار ذخیره میشود. علاوهبر آن، دادههای موجود در جدولهای مختلف را میتوان بدون نیاز به تکرار اطلاعات در یک نمای واحد با یکدیگر ترکیب کرد.
امروزه پایگاههای داده رابطهای از رایجترین انواع پایگاههای داده هستند. این پایگاهها برای مدیریت مجموعه دادههای ساختاریافته با قالب استاندارد، مانند تراکنشهای مالی یا اطلاعات تماس کاربران بسیار مناسب هستند.
دسته جدیدتری از پایگاههای داده رابطهای که با عنوان SQLجدید شناخته میشوند تلاش میکنند با استفاده از معماری پایگاه داده توزیعشده مقیاسپذیری مدل رابطهای را افزایش دهند. در این معماری دادهها میان چندین سرور پایگاه داده توزیع میشوند.
مثال پایگاه داده رابطهای: سیستمهای بانکی مانند سامانههای بانک ملت و سپهر
در سیستمهای بانکی، دادههای مشتریان، حسابها، تراکنشها و وامها با یکدیگر ارتباط دقیق و ساختاریافتهای دارند. برای مثال هر مشتری میتواند چندین حساب داشته باشد، هر حساب شامل تراکنشهای متعددی است و هر تراکنش به یک شعبه خاص مرتبط است. پایگاه داده رابطهای با استفاده از جداول مرتبط و کلیدهای خارجی، یکپارچگی و صحت این دادهها را تضمین میکند. از اهمیت این دیتابیسها میتوان به مدیریت دقیق ارتباط بین موجودیتها، جلوگیری از تناقض دادهای و امکان اجرای کوئریهای پیچیده روی چندین جدول بهصورت همزمان اشاره کرد.

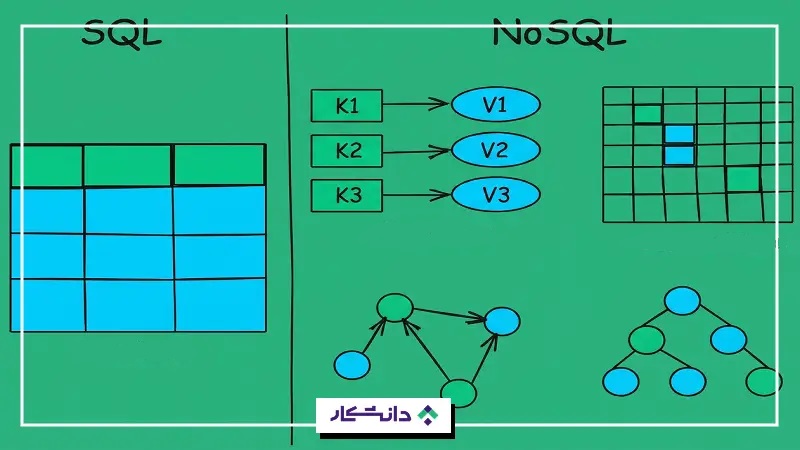
پایگاههای داده غیررابطهای یا NoSQL
پایگاه داده غیررابطهای دادهها را در قالبی ثابت و سختگیرانه، مانند جدول، ذخیره نمیکند. این پایگاه داده NoSQL نیز نام دارد و معمولا برای پیمایش و مدیریت دادهها به SQL نیاز ندارند.
پایگاههای داده غیررابطهای برای پشتیبانی از دادههای بدون ساختار و نیمهساختاریافته به وجود آمدهاند. مناسب دادههایی مانند متنهای آزاد و تصاویر است که راحت در جدولهای رابطهای جای نمیگیرند. انواع رایج پایگاههای داده غیررابطهای عبارتاند از:
- پایگاههای داده گرافی (Graph Databases): دادهها را بهصورت گرهها برای نمایش موجودیتها و اِجها (Edges) برای نمایش روابط میان آنها ذخیره میکنند. این پایگاههای داده اغلب برای ردیابی ارتباطات و روابط، مانند ارتباط میان کاربران یک شبکه اجتماعی، مورد استفاده قرار میگیرند.
- پایگاههای داده سندگرا (Document Databases): دادهها را در قالب اسناد ذخیره میکنند. این اسناد میتوانند در فرمتهایی مانند XML، JSON و BSON باشند. پایگاههای داده سندگرا در سیستمهای مدیریت محتوا بسیار رایج هستند.
- پایگاههای داده کلید-مقدار (Key-Value Databases): اطلاعات را بهصورت جفتهای کلید و مقدار ذخیره میکنند. در این ساختار، کلیدها شناسههای منحصربهفردی هستند (مانند شناسه یک سبد خرید آنلاین) و مقادیر شامل مجموعهای از دادهها (مانند اقلام موجود در آن سبد خرید) هستند.
- پایگاههای داده ستونگسترده (Wide-Column Databases): از سطرها و ستونها مشابه پایگاههای داده رابطهای استفاده میکنند. اما در پایگاه داده ستونگسترده هر سطر میتواند مجموعه متفاوتی از ستونها داشته باشد و اطلاعاتی متفاوت از سایر سطرها را ذخیره کند. این نوع پایگاه داده برای پشتیبانی از انبارهای داده (Data Warehouse) استفاده میشوند چرا که دادهها باید از منابع مختلف استخراج و در یک محل متمرکز شوند.
برای آشنایی بیشتر با مفاهیم این بخش شرکت در دوره SQL Server را به شما پیشنهاد میدهیم.
مثال پایگاه داده غیررابطهای (NoSQL): سیستمهایی مانند دیوار و آپارات
در پلتفرمهایی مثل دیوار، دادهها ساختار ثابت و یکسانی ندارند؛ آگهی یک خودرو شامل ویژگیهایی مانند مدل و کیلومتر است، در حالی که آگهی یک ملک شامل متراژ و تعداد اتاق است. پایگاه داده NoSQL برخلاف نوع رابطهای، نیازی به ساختار از پیش تعریفشده ندارد و انعطاف بالایی در ذخیرهسازی این نوع دادههای متنوع و حجیم ارائه میدهد. از اهمیت این دیتابیسها میتوان به مقیاسپذیری بالا، سرعت پردازش حجم زیاد دادهها و توانایی مدیریت دادههای بدون ساختار مشخص مانند تصاویر، متنهای کاربران و لاگهای سیستمی اشاره کرد.
پایگاه داده شیگرا
پایگاههای داده شیگرا با اسم پایگاههای داده مبتنیبر اشیا هم شناخته میشوند. این پایگاهها دادهها را بهصورت اشیا و طبق مفاهیم برنامهنویسی شیگرا ذخیره میکنند.
اشیا مجموعهای از اطلاعات و کدهای مرتبط هستند. هر شی نماینده یک موجودیت است. اشیا در قالب کلاسها گروهبندی میشوند و ویژگیهای مشخصی برای توصیف خصوصیات و متدهایی برای تعریف رفتار خود دارند. برای مثال یک شی در کلاس گربه میتواند ویژگیهایی مانند رنگ و وزن و متدهایی مانند خرخر کردن و شکار کردن داشته باشد.
پایگاههای داده شیگرا در دهه ۱۹۹۰ همزمان با گسترش برنامهنویسی شیگرا محبوب شدند. پایگاههای داده رابطهای میتواند برای برخی از برنامههای توسعهیافته با زبانهای شیگرا پر از چالش باشد. زیرا در این روش اشیای داده باید برای ذخیرهسازی به جدول تبدیل شوند. پایگاههای داده شیگرا به توسعهدهندگان کمک میکند با این مشکل مواجه نشوند.
مثال پایگاه داده شیگرا: سیستمهایی مانند بازیهای آنلاین و شبیهسازهای صنعتی
در بازیهای آنلاین مانند بازیهای تولیدشده توسط استودیوهای ایرانی مثل «کافه بازار» یا سیستمهای شبیهسازی صنعتی، هر شیء در سیستم (مثل شخصیت بازی، سلاح یا آیتم) ویژگیها و رفتارهای خاص خود را دارد. برای مثال یک شخصیت بازی علاوهبر داشتن ویژگیهایی مانند سطح انرژی و موقعیت مکانی، قابلیتهایی مثل حرکت کردن، حمله کردن و تعامل با محیط را هم دارد. پایگاه داده شیگرا همین ساختار شیگرا را برای ذخیرهسازی دادهها به کار میگیرد و نیازی به تبدیل اشیای برنامه به جداول رابطهای نیست. از اهمیت این دیتابیسها میتوان به حفظ یکپارچگی بین داده و رفتار اشیا، کاهش پیچیدگی در برنامهنویسی و عملکرد بالا در سیستمهایی که دادههای پیچیده و تو در تو دارند اشاره کرد.
پایگاههای داده برداری
پایگاههای داده برداری اطلاعات را بهصورت آرایههایی از اعداد یا بردار ذخیره میکنند. این بردارها طبق میزان شباهت به یکدیگر گروهبندی میشوند. برای مثال یک مدل هواشناسی ممکن است دمای حداقل، میانگین و حداکثر روز را بهصورت بردار [۸۵، ۷۷، ۶۲] ذخیره کند.
بردارها میتوانند اشیای پیچیدهای مانند کلمات، تصاویر، ویدیوها و فایلهای صوتی را نمایش دهند. این دادههای برداری با ابعاد بالا نقش مهمی در یادگیری ماشین (Machine Learning)، پردازش زبان طبیعی (NLP) و سایر وظایف مرتبط با هوش مصنوعی دارند.
از رایجترین کاربردهای پایگاههای داده برداری میتوان به هوش مصنوعی و یادگیری ماشین اشاره کرد. بهعنوان مثال، بسیاری از پیادهسازیهای چارچوبهای تولید مبتنیبر بازیابی اطلاعات (RAG) که به مدلهای زبانی بزرگ (LLMs) اجازه میدهند اطلاعات را از یک پایگاه دانش خارجی بازیابی کنند، از پایگاههای داده برداری استفاده میکنند.
مثال پایگاه داده برداری: سیستمهای جستجوی هوشمند و توصیهگر مانند دیجیکالا و اسنپ
در پلتفرمهایی مانند دیجیکالا، وقتی کاربر عبارتی مثل «گوشی ارزان با دوربین خوب» را جستجو میکند، سیستم باید محصولاتی را پیدا کند که از نظر معنایی به این درخواست نزدیک هستند، نه اینکه حتما شامل همین کلمات باشد. پایگاه داده برداری دادهها را بهصورت بردارهای عددی چندبعدی (Embedding) بدون تغییر معنا و مفهوم ذخیره میکند. سپس با محاسبه شباهت بین این بردارها، نزدیکترین نتایج را با سرعت بالا بازمیگرداند. از اهمیت این دیتابیسها میتوان به جستجوی معنایی، سیستمهای توصیهگر شخصیسازیشده، تشخیص تصاویر مشابه و پشتیبانی از مدلهای هوش مصنوعی و زبانی بزرگ اشاره کرد. پایگاههای داده سنتی چنین قابلیتی ندارند.
پایگاههای داده ابری
این نوع پایگاه داده در محیط رایانش ابری میزبانی میشوند. هر نوع پایگاه داده، از جمله رابطهای، غیررابطهای و سایر انواع میتواند بهصورت ابری پیادهسازی شود. دو نوع اصلی پایگاه داده ابری وجود دارد. نوع اول و سادهتر، سیستم پایگاه دادهای است که توسط خود سازمان مدیریت میشود اما در فضای ابری اجرا میشود. نوع دوم با عنوان پایگاه داده به عنوان سرویس (DBaaS) شناخته میشود.
سرویس رایانش ابری DBaaS به کاربران امکان میدهد بدون نیاز به مدیریت مستقیم سیستم، از نرمافزارهای پایگاه داده استفاده کنند. ارائهدهندگان DBaaS مجموعهای از خدمات از جمله ارتقا، پشتیبانگیری، امنیت پایگاه داده و سایر خدمات مرتبط را ارائه میدهند.
پایگاههای داده ابری نسبت به پایگاههای داده محلی (On-Premises) مقیاسپذیری بیشتری دارند. اگر سازمانی به فضای ذخیرهسازی بیشتر نیاز داشته باشد یا عملکرد سیستم کم شود، میتواند بهسرعت منابع بیشتری را در اختیار بگیرد.
مثال پایگاه داده ابری (DBaaS): سیستمهایی مانند اسنپ و تپسی
در اپلیکیشنهایی مانند اسنپ، تعداد کاربران در ساعات مختلف شبانهروز تغییر میکند و مدیریت زیرساخت سرورها و پایگاه داده برای تیم فنی کاری پرهزینه و زمانبر است. پایگاه داده ابری یا DBaaS (Database as a Service) مدلی است که در آن ارائهدهنده ابری مانند AWS، Azure یا Google Cloud تمام وظایف مدیریتی شامل نصب، پیکربندی، بهروزرسانی، پشتیبانگیری و تأمین امنیت را بر عهده میگیرد و توسعهدهندگان تنها از پایگاه داده استفاده میکنند. سرویسهایی مانند Amazon RDS، Google Cloud SQL و Azure Cosmos DB نمونههای شناختهشده این مدل هستند. از اهمیت این دیتابیسها میتوان به مقیاسپذیری خودکار با افزایش یا کاهش کاربران، حذف هزینه نگهداری سرور فیزیکی، پشتیبانگیری خودکار و دسترسی بالا از هر نقطه جغرافیایی اشاره کرد؛ ویژگیهایی که باعث میشود تیمهای فنی بدون نگرانی از زیرساخت، تنها روی توسعه محصول و بهبود تجربه کاربری تمرکز کنند.

سایر انواع پایگاههای داده
پایگاههای داده چندمدلی (Multimodel Databases) میتوانند بیش از یک نوع داده را ذخیره کنند. بهعنوان مثال IBM Db2 میتواند از دادههای JSON، XML متنی و مکانی در یک نمونه پایگاه داده واحد پشتیبانی کند.
پایگاههای داده درونحافظهای (In-Memory Databases) اطلاعات را در حافظه اصلی دستگاه یا RAM ذخیره میکنند. برنامهها معمولاً میتوانند دادهها را از RAM سریعتر از یک پایگاه داده سنتی بازیابی کنند. به همین دلیل این نوع پایگاههای داده اغلب برای ذخیرهسازی موقت (Caching) پردازش دادههای بلادرنگ (Real-Time) استفاده میشوند. با این حال، ظرفیت ذخیرهسازی آنها محدودتر است و به دلیل ناپایدار بودن ماهیت RAM، احتمال از دست رفتن دادهها بیشتر است.
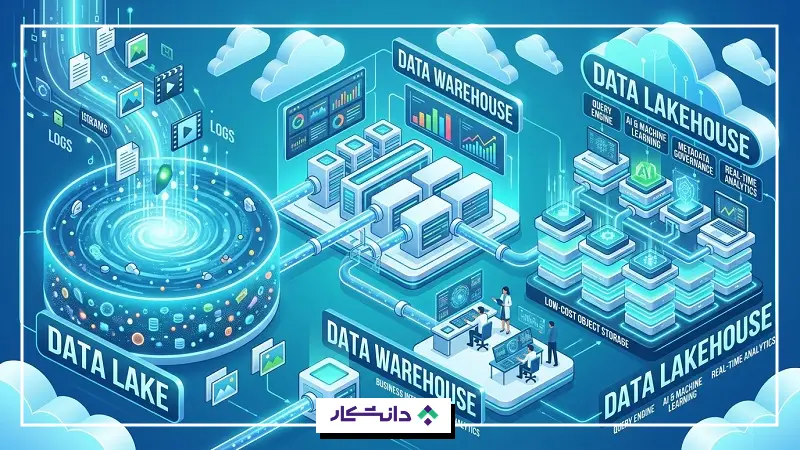
مقایسه پایگاه داده با دریاچه داده، انبارهای داده و data lakehouses
پایگاههای داده تنها راه سازماندهی دادهها نیستند و سازمانها اغلب از انواع مختلف مخازن داده برای پشتیبانی از اهداف و فعالیتهای گوناگون استفاده میکنند. پایگاههای داده در درجه اول برای ثبت خودکار دادهها، اجرای سریع پرسوجوها و پردازش تراکنشها طراحی شدهاند.
- دریاچههای داده (Data Lakes): محیطهای ذخیرهسازی کمهزینهای هستند که برای مدیریت حجم عظیمی از دادههای خام ساختاریافته و بدون ساختار طراحی شدهاند. برخلاف پایگاههای داده، دریاچههای داده معمولاً دادهها را پاکسازی، اعتبارسنجی یا نرمالسازی نمیکنند. این مخازن حجم بسیار زیادی از دادهها را برای فعالیتهایی مانند آموزش مدلهای هوش مصنوعی و تحلیل کلاندادهها (Big Data Analytics) نگهداری میکنند؛ حوزههایی که عملکرد بلادرنگ اهمیت کمتری دارد.
- انبارهای داده (Data Warehouse): برای پشتیبانی از تحلیل داده، هوش تجاری و پروژههای علم داده طراحی شدهاند. انبارهای داده دادهها را از پایگاههای داده مختلف جمعآوری کرده، پاکسازی و آمادهسازی میکنند تا برای استفاده آماده باشند.
- دریاچهخانههای داده (Data Lakehouse): قابلیتهای دریاچههای داده و انبارهای داده را در یک راهکار واحد مدیریت داده ترکیب میکنند. یک دریاچهخانه داده، ذخیرهسازی کمهزینه را با یک موتور پرسوجوی پرسرعت و سیستم هوشمند مدیریت فراداده (Metadata Governance) ترکیب میکند. این ویژگی به سازمانها امکان میدهد حجم زیادی از دادههای ساختاریافته و بدون ساختار را ذخیره کرده و بهراحتی از آنها در پروژههای هوش مصنوعی(AI)، یادگیری ماشین (ML) و تحلیل داده استفاده کنند.
پایگاه داده چگونه کار میکند؟
سیستم ذخیرهسازی دادهها که دادهها را بهصورت فیزیکی یا منطقی نگهداری میکند و سیستم مدیریت پایگاه داده که به کاربران امکان تعامل با مجموعه دادههای ذخیرهشده را میدهد دو بخش اصلی پایگاه داده هستند. البته میتوان اجزای یک سیستم پایگاه داده را با جزئیات بیشتری نیز بررسی کرد تا درک عمیقتری از نحوه عملکرد و ساختار داخلی پایگاه داده به دست آورد.
سختافزار پایگاه داده
پایگاههای داده باید دادههای خود را در جایی و روی نوعی سختافزار ذخیره کنند. با این حال، به دستگاههای تخصصی و ویژهای نیاز ندارند. اما بیشتر سیستمهای پایگاه داده از نرمافزارهای پایگاه دادهای تشکیل شدهاند که روی یک رایانه، سرور یا دستگاه دیگر اجرا میشوند. دستگاه، سختافزار فیزیکی لازم برای اجرای پایگاه داده را فراهم میکند و نرمافزار مسئول سازماندهی منطقی دادهها است. برای مثال، نرمافزار میتواند دادهها را در یک پایگاه داده رابطهای به شکل جدول یا در یک پایگاه داده گرافی به شکل گراف سازماندهی کند.
یک پایگاه داده و برنامههایی که از آن استفاده میکنند میتوانند روی یک سختافزار واحد اجرا شوند، اما امروزه بیشتر سیستمهای پایگاه داده از معماری چندلایه (Multitier Architecture) استفاده میکنند که در آن سرورهای برنامه (Application Servers) از سرورهای پایگاه داده (Database Servers) جدا هستند. این ساختار مقیاسپذیری و قابلیت اطمینان بیشتری فراهم میکند. سرورهای برنامه و پایگاه داده میتوانند مستقل از یکدیگر توسعه پیدا کنند و بروز مشکل در یک لایه الزاما روی سایر لایهها تأثیر نمیگذارد.
مدلهای داده و مدلهای پایگاه داده
مدل داده (Data Model) نمایشی بصری از یک سیستم اطلاعاتی است. مدیران و طراحان پایگاه داده از این مدلها بهعنوان ابزارهای مفهومی برای درک نوع دادههایی که باید مدیریت شوند، روابط میان دادهها و بهترین روش سازماندهی آنها استفاده میکنند. مدل داده به شناسایی مدل مناسب پایگاه داده کمک میکند. مدل پایگاه داده پیادهسازی عملی سیستم پایگاه داده است و شامل الزامات فنی و قالبهای ذخیرهسازی میشود. برای مثال، یک مدل داده منطقی ممکن است در نهایت به یک پایگاه داده رابطهای تبدیل شود.
شِماهای پایگاه داده
شِمای پایگاه داده بهصورت فنی و منطقی مشخص میکند که دادهها چگونه در یک پایگاه داده سازماندهی شوند. شِما مدل داده را به مجموعهای از قوانین تبدیل میکند که پایگاه داده باید از آنها پیروی کند. برای مثال، در یک پایگاه داده رابطهای، شِما مواردی مانند نام جدولها، فیلدها، انواع داده و روابط میان آنها را تعریف میکند. شِماها میتوانند بهصورت نمودارهای بصری نمایش داده شوند، با دستورات SQL یا بهترین زبانهای برنامهنویسی نوشته شوند یا به روشهای دیگر تعریف شوند. نحوه تعریف آنها به نوع شِما و سیستم پایگاه داده بستگی دارد.
تمام سیستمهای پایگاه داده رابطهای شِما دارند. برخی از پایگاههای داده غیررابطهای نیز شِما دارند، برخی ندارند و برخی دیگر استفاده از آن را اختیاری میدانند.
سیستمهای مدیریت پایگاه داده
سیستم مدیریت پایگاه داده (DBMS) نرمافزاری است که به مدیران پایگاه داده، کاربران و برنامهها امکان میدهد بهراحتی با دادههای موجود در پایگاه داده تعامل داشته باشند. سیستمهای DBMS به کاربران اجازه میدهند وظایف مهم مدیریت داده را انجام دهند. از جمله قالببندی پایگاه دادهها میتوان به مدیریت فراداده (Metadata)، اجرای پرسوجوها و افزودن، بهروزرسانی یا حذف دادهها اشاره کرد.
برخی از DBMSها به اجرای تدابیر امنیتی هم کمک میکنند؛ مانند اعمال کنترلهای دسترسی به پایگاه داده و ثبت فعالیت کاربران. همچنین ممکن است عملکرد پایگاه داده را نیز پایش کنند.
همانند خود پایگاههای داده، سیستمهای DBMS هم انواع مختلفی دارند. برای مثال، سیستمهای مدیریت پایگاه داده رابطهای (RDBMS) برای پایگاههای داده رابطهای طراحی شدهاند، درحالیکه سیستمهای مدیریت پایگاه داده شیءگرا (OODBMS) برای مدیریت پایگاههای داده شیءگرا به کار میروند. برخی از رایجترین سیستمهای مدیریت پایگاه داده عبارتاند از:
- MySQL یک RDBMS متنباز است که اغلب در وبسایتهای تجارت الکترونیک و سایر برنامههای تحت وب استفاده میشود.
- PostgreSQL با قابلیت توسعهپذیری و اطمینان بالای تراکنشها شناخته میشود.
- Microsoft SQL Server بهطور گسترده در سازمانهایی که از زیرساختهای مایکروسافت استفاده میکنند به کار میرود.
- Oracle Database یک DBMS چندمدلی است که میتواند دادههای ساختاریافته و بدون ساختار را مدیریت کند.
- IBM Db2 یک سیستم پایگاه داده بومی ابری است که قابلیتهایی مانند مدیریت پایگاه داده، انبار داده، ذخیرهسازی و امکانات دیگر برای پشتیبانی از تحلیل بلادرنگ و برنامههای هوش مصنوعی را ارائه میدهد.
زبانهای پایگاه داده
زبانهای پایگاه داده، زبانهای برنامهنویسی تخصصی هستند که برای تعامل با پایگاههای داده استفاده میشوند. این زبانها ساختاری مشخص برای نوشتن پرسوجوها و بازیابی، ترکیب، بهروزرسانی یا استفاده از دادهها در اختیار کاربران قرار میدهند.
رایجترین زبان پایگاه داده، زبان پرسوجوی ساختاریافته (SQL) است که بیشتر پایگاههای داده رابطهای از آن استفاده میکنند. SQL در دهه ۱۹۷۰ توسط دانشمندان IBM توسعه یافت و به مدیران پایگاه داده، توسعهدهندگان و تحلیلگران داده کمک میکند وظایفی مانند تعریف داده، کنترل دسترسی، اشتراکگذاری داده، یکپارچهسازی داده و اجرای پرسوجوهای تحلیلی را انجام دهند.
سایر زبانهای پایگاه داده شامل OQL (Object Query Language) برای پایگاههای داده شیءگرا و XQuery برای پایگاههای داده اسناد XML هستند.
همچنین برخی زبانها اختصاصی برای یک پایگاه داده خاص طراحی شدهاند؛ مانند MQL (MongoDB Query Language) برای MongoDB و (Cassandra Query Language) CQL برای Apache Cassandra.
دلیل اهمیت پایگاه داده چیست؟
پایگاههای داده برای بسیاری از فناوریهایی که امروزه مردم به آنها متکی هستند، حیاتیاند؛ از اپلیکیشنهای بانکی که تراکنشهای مالی را در پایگاههای داده رابطهای ثبت میکنند تا دستیارهای هوش مصنوعی که برای افزایش دقت خود از پایگاههای داده برداری استفاده میکنند. پایگاههای داده تا این اندازه رایج هستند، زیرا نقش مهمی در پشتیبانی از موارد زیر دارند:
- قابلیت استفاده از دادهها (Data Usability)
- یکپارچگی دادهها (Data Integrity)
- امنیت دادهها و مطابقت با مقررات (Data Security and Compliance)
۱. قابلیت استفاده از دادهها
امروزه سازمانها حجم عظیمی از دادهها را در اختیار دارند، اما این موضوع زمانی ارزشمند است که افراد بتوانند از آن دادهها استفاده کنند. در واقع، طبق گزارش IBM Data Differentiator، حدود ۶۸ درصد از دادههای سازمانی هرگز مورد تحلیل قرار نمیگیرند. در بسیاری از موارد، دلیل این مسئله آن است که افراد از وجود این دادهها آگاه نیستند یا سیلوهای دادهای (Data Silos) مانع دسترسی به آنها میشوند.
پایگاههای داده به سازمانها این امکان را میدهند که مجموعهای از دادهها را گردآوری، ذخیره و بهصورت متمرکز مدیریت کنند. همچنین میتوانند بخش زیادی از فرآیند جمعآوری دادهها، از جمله ثبت رویدادها و تراکنشها بهصورت بلادرنگ (Real-Time)، را خودکار کنند.
نحوه انتخاب، طراحی و پیادهسازی پایگاه داده میتواند در موفقیت یا شکست بسیاری از ابتکارات مهم کسبوکار نقش تعیینکننده داشته باشد. زمانی که دادهها بهخوبی سازماندهی شده و بهراحتی در دسترس باشند، میتوانند به تصمیمگیری بهتر کمک کنند، پروژههای هوش تجاری را تقویت کنند و زیرساخت لازم برای پروژههای هوش مصنوعی و یادگیری ماشین را فراهم آورند.
۲. یکپارچگی دادهها
پایگاههای داده در مقایسه با صفحات گسترده و سایر روشهای دستی ثبت اطلاعات، مزایای قابلتوجهی ارائه میدهند؛ زیرا روشهای دستی در معرض خطا، تکرار دادهها و ناهماهنگی اطلاعات قرار دارند.
از آنجا که پایگاههای داده بهصورت متمرکز مدیریت میشوند، اعمال قوانین پاکسازی و قالببندی دادهها، نظارت بر نحوه استفاده از دادهها و ردیابی منشأ و مسیر حرکت دادهها (Data Lineage) سادهتر میشود. همچنین دیگر نیازی به نگهداری و توزیع چندین نسخه از یک مجموعه داده وجود ندارد؛ نسخههایی که ممکن است بهمرور زمان با یکدیگر ناسازگار شوند. در عوض، همه کاربران، برنامهها و سیستمها از یک مخزن داده مشترک استفاده میکنند.
در نهایت، پایگاههای داده به ایجاد ارتباط میان انواع مختلف کاربران و سامانهها، از جمله افراد، نرمافزارها وAPIها، با دادههای دقیق، پاکسازیشده و قابل اعتماد کمک میکنند.
۳. امنیت دادهها و مطابقت با مقررات
سازمانها بسته به موقعیت جغرافیایی و حوزه فعالیت خود، ملزم به رعایت قوانین و مقررات مربوط به حفاظت و حریم خصوصی دادهها هستند. از جمله این مقررات میتوان به قانون قابلیت انتقال و پاسخگویی بیمه سلامت آمریکا (HIPAA) و مقررات عمومی حفاظت از دادههای European Union (GDPR) اشاره کرد.
علاوهبر الزامات قانونی، سازمانها از نظر تجاری نیز علاقهمند به جلوگیری از دسترسی غیرمجاز به دادههای خود هستند. بر اساس گزارش هزینه نقض دادهIBM، میانگین هزینه هر رخداد نقض داده حدود ۴٫۸۸ میلیون دلار است که شامل خسارتهای ناشی از ازدسترفتن کسبوکار، توقف سیستمها، هزینههای بازیابی و سایر پیامدها میشود.
پایگاههای داده میتوانند با اجرای مکانیزمهای امنیتی مختلف به حفاظت از دادهها و رعایت الزامات قانونی کمک کنند. یکی از این مکانیزمها کنترل دسترسی مبتنی بر نقش (Role-Based Access Control) یا RBAC است که اطمینان میدهد تنها کاربران مجاز به دادههای موردنیاز خود دسترسی داشته باشند.
نقش پایگاه داده در ابتکارهای هوش مصنوعی
۷۵ درصد از مدیران عامل معتقدند در آینده، استفاده از پیشرفتهترین فناوریهای هوش مصنوعی مولد (Generative AI) یکی از عوامل تعیینکننده در ایجاد مزیت رقابتی برای سازمانها خواهد بود. برای پشتیبانی از چنین سیستمهای پیشرفتهای، سازمانها باید بتوانند حجم عظیمی از دادههای ساختاریافته و بدون ساختار را ذخیره، مدیریت و حاکمیتگذاری (Governance) کنند. دستیابی به این هدف تنها با استفاده از سیستمهای پایگاه داده مناسب امکانپذیر است.
انواع مختلف پایگاههای داده میتوانند به شیوههای متفاوتی از پروژههای هوش مصنوعی و یادگیری ماشین پشتیبانی کنند. برای مثال، پایگاههای داده برداری برای پیادهسازی چارچوبهای تولید مبتنی بر بازیابی اطلاعات (RAG) استفاده میشوند که میتوانند به کاهش پدیده توهم در مدلهای هوش مصنوعی کمک کنند. پایگاههای داده کلید-مقدار (Key-Value Databases) میتوانند سرعت بازیابی و پردازش دادهها را افزایش دهند و پایگاههای داده درونحافظهای (In-Memory Databases) هم از ذخیرهسازی موقت و تحلیلهای جریانی (Streaming Analytics) پشتیبانی میکنند.
نکات انتخاب پایگاه داده
عوامل مختلفی میتوانند بر انتخاب نوع پایگاه داده برای یک پروژه یا ابتکار خاص تأثیر بگذارند. برخی از مهمترین این عوامل عبارتاند از:
- نوع داده (Type of Data): هر نوع پایگاه داده برای مدیریت برخی از دادهها مناسبتر از سایر گزینهها است. برای مثال، یک پایگاه داده گرافی معمولاً برای نمایش و تحلیل روابط میان دادهها انتخاب بهتری نسبت به یک پایگاه داده SQL محسوب میشود.
- هدف استفاده (Purpose): انواع مختلف پایگاه داده برای کاربردهای متفاوتی طراحی شدهاند. برای نمونه، یک پایگاه داده برداری اغلب بهترین گزینه برای پیادهسازی یک چارچوب RAG است.
- نیازمندیهای عملکردی (Performance Requirements): اگر یک برنامه بهطور مداوم دادهها را بهصورت بلادرنگ (Real-Time) دریافت و پردازش میکند، سازمان به پایگاه دادهای نیاز دارد که سرعت اجرای پرسوجوها را بهینه کند. اما اگر هدف صرفاً ذخیرهسازی دادهها پیش از انتقال آنها به یک انبار داده باشد، عملکرد ممکن است اهمیت کمتری داشته باشد.
- هزینه (Price): حجم دادههایی که باید ذخیره شوند، قالب آنها و سطح عملکرد موردنیاز همگی میتوانند بر هزینه نهایی پایگاه داده تأثیر بگذارند
- مقیاسپذیری (Scalability): برخی از پایگاههای داده فقط از مقیاسپذیری عمودی (Vertical Scaling) پشتیبانی میکنند؛ به این معنا که برای افزایش ظرفیت باید منابع بیشتری به همان سرور یا دستگاه موجود اضافه شود. در مقابل، برخی دیگر از مقیاسپذیری افقی (Horizontal Scaling) پشتیبانی میکنند؛ یعنی میتوان با افزودن سرورهای بیشتر، پایگاه داده را بهصورت توزیعشده گسترش داد.
منبع: ibm.com
