یادگیری تقویتی (RL یا Reinforcement Learning) نوعی فرایند یادگیری ماشین است که در آن عاملهای مستقل با تعامل با محیط خود، یاد میگیرند چگونه تصمیم بگیرند. عامل مستقل هر سیستمی است که بتواند بدون دریافت دستور مستقیم از یک کاربر انسانی، بر اساس محیط اطرافش تصمیم بگیرد و عمل کند. رباتها و خودروهای خودران نمونههایی از عاملهای مستقل هستند. در یادگیری تقویتی، عاملهای مستقل بدون هیچگونه راهنمایی از سوی انسان و از طریق آزمون و خطا یاد میگیرند یک وظیفه را انجام دهند. این روش به مسائل تصمیمگیری ادامهدار در محیطهای نامطمئن میپردازد و ما را به توسعه هوش مصنوعی بسیار امیدوار میکند.
یادگیری نظارتشده و بدوننظارت
در منابع علمی، اکثرا یادگیری تقویتی با یادگیری نظارتشده و بدوننظارت مقایسه میشود.
یادگیری نظارتشده از دادههای تگدار که دستی آماده شدهاند استفاده میکند تا پیشبینی یا دستهبندی انجام دهد. در مقابل، یادگیری بدوننظارت تلاش میکند الگوهای پنهان را از دادههای بدون تگ، کشف و استخراج کند.
برخلاف یادگیری نظارتشده، یادگیری تقویتی از نمونههای مشخصشده رفتار درست یا نادرست استفاده نمیکند و با یادگیری بدوننظارت هم تفاوت دارد. در یادگیری تقویتی، مدل از طریق آزمونوخطا و بر اساس تابع پاداش یاد میگیرد، نه از طریق استخراج الگوهای پنهان از دادهها.
در روشهای یادگیری نظارتشده و بدون نظارت فرض میشود هر رکورد داده ورودی مستقل از سایر رکوردهای مجموعه داده است اما همه آنها از یک توزیع دادهای مشترک پیروی میکنند. این روشها یاد میگیرند پیشبینی کنند و عملکرد مدل نیز بر اساس بیشینهسازی دقت پیشبینی ارزیابی میشود.
در مقابل، یادگیری تقویتی یاد میگیرد چگونه عمل کند. این روش فرض میکند دادههای ورودی بهصورت وابسته به هم و در قالب دنبالههای مرتبشدهای از دادهها سازماندهی شدهاند که شامل وضعیت، عمل و پاداش هستند. بسیاری از کاربردهای الگوریتمهای یادگیری تقویتی تلاش میکنند روشهای یادگیری زیستی در دنیای واقعی را از طریق تقویت مثبت شبیهسازی کنند.
نکته مهم این است که اگرچه گاهی در منابع کمتر با هم مقایسه میشوند، یادگیری تقویتی با یادگیری خودنظارتی نیز تفاوت دارد. یادگیری خودنظارتی نوعی از یادگیری بدون نظارت است که از تگهای شبهواقعی استخراجشده از دادههای بدون تگ بهعنوان مبنای ارزیابی دقت مدل استفاده میکند. اما در یادگیری تقویتی، نه برچسب شبهواقعی تولید میشود و نه مدل با یک حقیقت مبنا مقایسه میشود. این روش، یک روش دستهبندی نیست، بلکه یادگیرندهی عمل است. با این حال، ترکیب این دو رویکرد در برخی پژوهشها نتایج خوبی داشت.
مطلب مرتبط: ماشین لرنینگ با پایتون – هر آنچه باید بدانید
فرایند یادگیری تقویتی
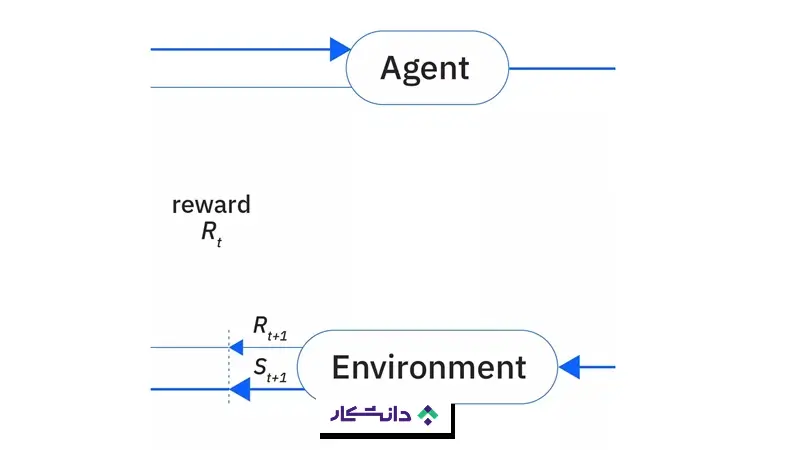
یادگیری تقویتی، که جزو مباحث مهم نقشه راه هوش مصنوعی است، در اصل بر پایهی رابطه میان سه مؤلفه عامل، محیط و هدف شکل میگیرد. در منابع علمی، این رابطه در قالب فرایند تصمیمگیری مارکوف صورتبندی میشود. در یادگیری تقویتی، عامل از طریق تعامل مستقیم با محیط دربارهی مسئله یاد میگیرد. روند کار به این ترتیب است:
- محیط اطلاعاتی دربارهی وضعیت فعلی خود در اختیار عامل قرار میدهد.
- عامل بر اساس این وضعیت تصمیم میگیرد چه عملی انجام دهد.
- محیط در پاسخ به این عمل، یک پاداش یا تنبیه ارائه میکند.
- عامل با توجه به این بازخورد، استراتژی خود را برای تصمیمهای بعدی تنظیم میکند.
اگر عملی منجر به دریافت پاداش شود، احتمال اینکه عامل در موقعیتهای مشابه آینده همان عمل را تکرار کند افزایش مییابد. این چرخه برای هر وضعیت جدید تکرار میشود. در طول زمان، عامل از طریق پاداشها و تنبیهها یاد میگیرد چگونه در محیط به شکلی عمل کند که به هدف مشخصشده دست پیدا کند.
در فرایندهای تصمیمگیری مارکوف، فضای حالت به تمام اطلاعاتی اشاره دارد که وضعیت محیط در اختیار عامل قرار میدهد. همچنین فضای عمل شامل تمام اقدامهای ممکنی است که عامل میتواند در یک وضعیت مشخص انجام دهد.
مبادلهی اکتشاف – بهرهبرداری
در یادگیری تقویتی دادههای ورودیِ برچسبخوردهای برای هدایت رفتار عامل وجود ندارد، عامل باید محیط خود را اکتشاف کند؛ یعنی اعمال جدید را امتحان کند تا متوجه شود کدامیک پاداش دریافت میکنند. عامل بر اساس سیگنالهای پاداش یاد میگیرد اقدامهایی را ترجیح دهد که قبلا برای آنها پاداش گرفته است تا سود خود را بیشینه کند. اما در عین حال، باید به اکتشاف وضعیتها و اقدامهای جدید هم ادامه دهد، زیرا این تجربههای تازه به بهبود تصمیمگیری او کمک میکند.
بنابراین الگوریتمهای یادگیری تقویتی مستلزم آن هستند که عامل همزمان:
- از دانش مربوط به وضعیت–اقدامهای قبلی پاداشگرفته بهرهبرداری کند،
- و سایر وضعیت–اقدامها را هم کشف کند.
عامل نمیتواند فقط یکی از این دو رویکرد را دنبال کند. او باید دائم اقدامهای جدید را امتحان کند و در عین حال، اقدام یا زنجیرهای از اقدامها را ترجیح دهد که بیشترین پاداش تجمعی را تولید میکنند.
مؤلفههای یادگیری تقویتی
علاوه بر سهگانهی عامل–محیط–هدف، چهار زیرعنصر اصلی مسائل یادگیری تقویتی را مشخص میکنند.
- سیاست: این مولفه رفتار عامل یادگیری تقویتی را با نگاشت وضعیتهای درکشدهی محیط به اقدامهای مشخصی که عامل باید در آن وضعیتها انجام دهد تعریف میکند. سیاست میتواند به شکل یک تابع ساده یا یک فرایند محاسباتی پیچیدهتر باشد. برای مثال، سیاستی که یک خودروی خودران را هدایت میکند ممکن است «تشخیص عابر پیاده» را به «اقدام توقف» نگاشت کند.
- سیگنال پاداش: مولفه سیگنال پاداش هدف مسئلهی یادگیری تقویتی را مشخص میکند. هر یک از اقدامهای عامل یادگیری تقویتی یا از محیط پاداش دریافت میکند یا نمیکند. تنها هدف عامل این است که پاداش تجمعی خود را از محیط بیشینه کند. برای خودروهای خودران، سیگنال پاداش میتواند شامل کاهش زمان سفر، کاهش برخوردها، باقیماندن در جاده و در خط صحیح، اجتناب از کاهش یا افزایش سرعت شدید و مواردی از این دست باشد. این مثال نشان میدهد که یادگیری تقویتی میتواند برای هدایت یک عامل، چندین سیگنال پاداش را به کار گیرد.
- تابع ارزش: سیگنال پاداش با تابع ارزش تفاوت دارد، به این صورت که اولی بیانگر منفعت فوری است، در حالی که دومی منفعت بلندمدت را مشخص میکند. ارزش به مطلوبیت یک وضعیت با در نظر گرفتن تمام وضعیتهایی (به همراه پاداشهای مربوط به آنها) اشاره دارد که احتمالا پس از آن رخ خواهند داد. یک خودروی خودران ممکن است بتواند با خروج از خط، رانندگی روی پیادهرو و شتابگیری سریع، زمان سفر را کاهش دهد، اما این سه اقدام اخیر ممکن است تابع ارزش کلی آن را کاهش دهند. بنابراین، خودرو بهعنوان یک عامل یادگیری تقویتی ممکن است زمان سفر اندکی طولانیتر را بپذیرد تا پاداش خود را در آن سه حوزه افزایش دهد.
- مدل: این یک زیرعنصر اختیاری در سیستمهای یادگیری تقویتی است. مدلها به عاملها اجازه میدهند رفتار محیط را برای اقدامهای احتمالی پیشبینی کنند. سپس عاملها از پیشبینیهای مدل استفاده میکنند تا بر اساس پیامدهای بالقوه، مسیرهای ممکن اقدام را تعیین کنند. این میتواند همان مدلی باشد که خودروی خودران را هدایت میکند و به آن کمک میکند بهترین مسیرها را پیشبینی کند، بداند با توجه به موقعیت و سرعت خودروهای اطراف چه انتظاری باید داشته باشد و موارد مشابه. برخی رویکردهای مبتنی بر مدل در مراحل اولیهی یادگیری از بازخورد مستقیم انسانی استفاده میکنند و سپس به یادگیری خودمختار تغییر میکنند.
یادگیری آنلاین در برابر آفلاین
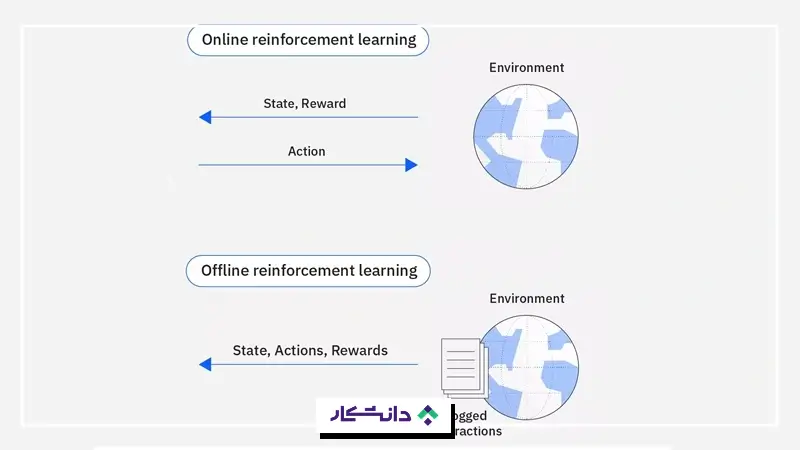
دو روش کلی وجود دارد که یک عامل از طریق آنها برای یادگیری سیاستها داده جمعآوری میکند:
- آنلاین: در این روش، عامل دادهها را مستقیم از طریق تعامل با محیط اطراف خود جمعآوری میکند. این دادهها بهصورت تکرارشونده پردازش و جمعآوری میشوند، در حالی که عامل به تعامل خود با آن محیط ادامه میدهد.
- آفلاین: وقتی یک عامل دسترسی مستقیم به محیط ندارد، میتواند از طریق دادههای ثبتشده (لاگشده) از آن محیط یاد بگیرد. به این روش، یادگیری آفلاین گفته میشود. بخش بزرگی از پژوهشها به دلیل دشواریهای عملی در آموزش مدلها از طریق تعامل مستقیم با محیطها، به سمت یادگیری آفلاین گرایش پیدا کردهاند.
مطلب مرتبط: تفاوت هوش مصنوعی و ماشین لرنینگ در چیست؟
انواع یادگیری تقویتی
یادگیری تقویتی حوزهای پویا و در حال توسعه در پژوهش است و به همین دلیل، توسعهدهندگان رویکردهای متعددی برای آن ارائه کردهاند. با این حال، سه روش پرکاربرد و بنیادی که بهطور گسترده مورد بحث قرار میگیرند عبارتاند از: برنامهنویسی پویا، مونتکارلو و یادگیری تفاوت زمانی.
برنامهنویسی پویا
برنامهنویسی پویا وظایف بزرگتر را به وظایف کوچکتر تقسیم میکند. بنابراین، مسائل را بهصورت جریانهای کاری از تصمیمهای دنبالهدار که در گامهای زمانی گسسته اتخاذ میشوند مدلسازی میکند. هر تصمیم بر اساس وضعیت بعدیِ احتمالی که از آن ناشی میشود گرفته میشود. پاداش یک عامل (r) برای یک اقدام مشخص، بهعنوان تابعی از آن اقدام (a)، وضعیت فعلی محیط (s) و وضعیت بالقوهی بعدی (s′) تعریف میشود:

این تابع پاداش میتواند بهعنوان (بخشی از) سیاستی که اقدامات عامل را هدایت میکند مورد استفاده قرار گیرد. تعیین سیاست بهینه برای رفتار عامل، یکی از مؤلفههای اصلی روشهای برنامهنویسی پویا در یادگیری تقویتی است. در اینجا معادله بلمن مطرح میشود.
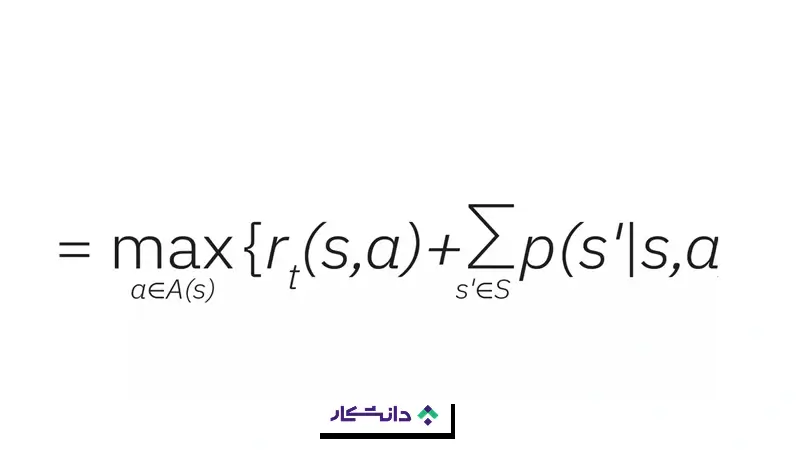
معادله بلمن به صورت زیر است:به طور خلاصه، این معادله را بهعنوان مجموع پاداش مورد انتظار از زمان
تا پایان جریان تصمیمگیری تعریف میکند. فرض میشود عامل از وضعیت
در زمان
شروع میکند. این معادله در نهایت پاداش در زمان
را به پاداش فوری
(یعنی همان فرمول پاداش) و مجموع پاداش مورد انتظار عامل تقسیم میکند. بنابراین عامل با انتخاب مداوم آن عملی که در هر وضعیت سیگنال پاداش دریافت میکند، تابع ارزش خود—که مجموع ارزش معادله بلمن است—را بیشینه میکند.
روش مونتکارلو
برنامهنویسی پویا مبتنی بر مدل است؛ به این معنا که یک مدل از محیط خود میسازد تا پاداشها را درک کند، الگوها را شناسایی کند و محیط را پیمایش کند. در مقابل، روش مونتکارلو محیط را جعبه سیاه فرض میکند و به همین دلیل بدون مدل (model-free) است.
در حالی که برنامهنویسی پویا وضعیتها و سیگنالهای پاداش احتمالی آینده را در تصمیمگیری پیشبینی میکند، روشهای مونتکارلو کاملاً مبتنی بر تجربه هستند و تنها از طریق تعامل با محیط، دنبالههای وضعیتها، اقدامها و پاداشها را نمونهبرداری میکنند. بنابراین مونتکارلو از طریق آزمون و خطا یاد میگیرد، نه از توزیعهای احتمالاتی.
مونتکارلو همچنین در تعیین تابع ارزش با برنامهنویسی پویا تفاوت دارد. برنامهنویسی پویا بیشترین پاداش تجمعی را با انتخاب مداوم اقدامات پاداشدادهشده در وضعیتهای متوالی به دست میآورد. در مقابل، مونتکارلو میانگین بازدهها برای هر جفت وضعیت–اقدام را محاسبه میکند. این بدان معناست که روش مونتکارلو باید صبر کند تا تمام اقدامات در یک اپیزود (یا افق برنامهریزی) تکمیل شوند، سپس تابع ارزش خود را محاسبه کرده و سیاست خود را بهروزرسانی کند.
یادگیری تفاوت زمانی
مطالعات علمی یادگیری تفاوت زمانی (TD) را ترکیبی از برنامهنویسی پویا و مونتکارلو توصیف میکنند. همانند برنامهنویسی پویا، TD سیاست خود را و همچنین برآوردهای مربوط به وضعیتهای آینده را پس از هر گام بهروزرسانی میکند و منتظر ارزش نهایی نمیماند. اما همانند مونتکارلو، TD از طریق تعامل مستقیم با محیط یاد میگیرد و از مدل استفاده نمیکند.
طبق نام خود، عامل یادگیری TD سیاست خود را بر اساس تفاوت بین پاداش پیشبینیشده و پاداش واقعی دریافتشده در هر وضعیت اصلاح میکند. یعنی، در حالی که برنامهنویسی پویا و مونتکارلو تنها پاداش دریافتشده را در نظر میگیرند، TD تفاوت بین انتظار خود و پاداش واقعی را نیز لحاظ میکند. با استفاده از این تفاوت، عامل بدون انتظار تا پایان افق برنامه، برآوردهای خود را برای گام بعدی بهروزرسانی میکند.
TD انواع مختلفی دارد. دو نوع برجسته آن عبارتاند از:
- SARSA: یک روش TD بر پایه سیاست است، به این معنا که سیاست حاکم بر تصمیمگیری را ارزیابی و بهبود میبخشد.
- Q-learning: یک روش TD خارج از سیاست است. روشهای خارج از سیاست دو سیاست دارند؛ یکی برای بهرهبرداری (سیاست هدف) و دیگری برای اکتشاف و تولید رفتار (سیاست رفتاری).
روشهای تکمیلی
روشهای بسیاری دیگر در یادگیری تقویتی وجود دارند. برنامهنویسی پویا یک روش مبتنی بر ارزش است، به این معنا که اقدامها را بر اساس مقادیر برآوردی خود و مطابق سیاستی که به دنبال بیشینهسازی تابع ارزش است، انتخاب میکند.
در مقابل، روشهای گرادیان سیاست، سیاست پارامتریافتهای یاد میگیرند که میتواند بدون مشورت با تابع ارزش اقدامها را انتخاب کند. این روشها مبتنی بر سیاست هستند و در محیطهای با ابعاد بالا مؤثرتر در نظر گرفته میشوند.
روشهای بازیگر–نقدگر از هر دو روش مبتنی بر ارزش و مبتنی بر سیاست استفاده میکنند. بازیگر سیاست گرادیان را مشخص میکند که تعیین کند چه اقدامهایی انجام شود، در حالی که «نقدگر» تابع ارزش برای ارزیابی اقدامها است. روشهای بازیگر–نقدگر اساساً نوعی TD محسوب میشوند. به طور مشخص، بازیگر–نقدگر ارزش یک اقدام را نه تنها بر اساس پاداش خود اقدام، بلکه با در نظر گرفتن ارزش وضعیت بعدی که به پاداش اقدام اضافه میشود، ارزیابی میکند. مزیت بازیگر–نقدگر این است که با پیادهسازی همزمان تابع ارزش و سیاست در تصمیمگیری، تعامل کمتری با محیط نیاز دارد.
مطلب مرتبط: رودمپ یادگیری ماشین لرنینگ – مراحل و منابع
مثالهایی از یادگیری تقویتی
از کاربردهای یادگیری تقویتی میتوان به مثالهای زیر اشاره کرد:
رباتیک
با توجه به اینکه یادگیری تقویتی بهطور مرکزی بر تصمیمگیری در محیطهای غیرقابل پیشبینی تمرکز دارد، یکی از حوزههای اصلی مورد علاقه در رباتیک است. برای انجام وظایف ساده و تکراری، تصمیمگیری ممکن است مستقیم و ساده باشد. اما وظایف پیچیدهتر، مانند شبیهسازی رفتار انسانی یا خودکارسازی رانندگی، مستلزم تعامل با محیطهای واقعی با تغییرپذیری و نوسان بالا هستند.
تحقیقات نشان میدهند که یادگیری تقویتی عمیق با شبکههای عصبی عمیق به انجام چنین وظایفی کمک میکند، بهویژه در زمینه عمومیتبخشی و نگاشت دادههای حسی با ابعاد بالا به خروجیهای کنترلشده سیستم.
مطالعات همچنین نشان میدهند که یادگیری تقویتی عمیق با رباتها به شدت به دادههای جمعآوریشده متکی است، و بنابراین پژوهشهای اخیر مسیرهایی برای جمعآوری دادههای دنیای واقعی و بازاستفاده از دادههای پیشین برای بهبود سیستمهای یادگیری تقویتی را بررسی میکنند.
پردازش زبان طبیعی
تحقیقات اخیر نشان میدهند که استفاده از تکنیکها و ابزارهای پردازش زبان طبیعی-مانند مدلهای زبان بزرگ (LLMs)- میتواند از طریق نمایش متنی محیطهای واقعی، عمومیتبخشی در سیستمهای یادگیری تقویتی را بهبود دهد.
مطالعات زیادی نشان میدهند که محیطهای متنی تعاملی، جایگزینهای مقرونبهصرفهای برای محیطهای سهبعدی ارائه میدهند، زمانی که هدف آموزش عاملهای یادگیری در وظایف تصمیمگیری متوالی باشد.
همچنین یادگیری تقویتی عمیق پایه تصمیمگیری متنی در چتباتها را فراهم میکند. در واقع، یادگیری تقویتی در بهبود پاسخهای گفتگویی چتباتها نسبت به سایر روشها عملکرد بهتری دارد.
منبع: ibm.com